
Erhalte unsere neuesten Artikel und Updates bequem per E-Mail
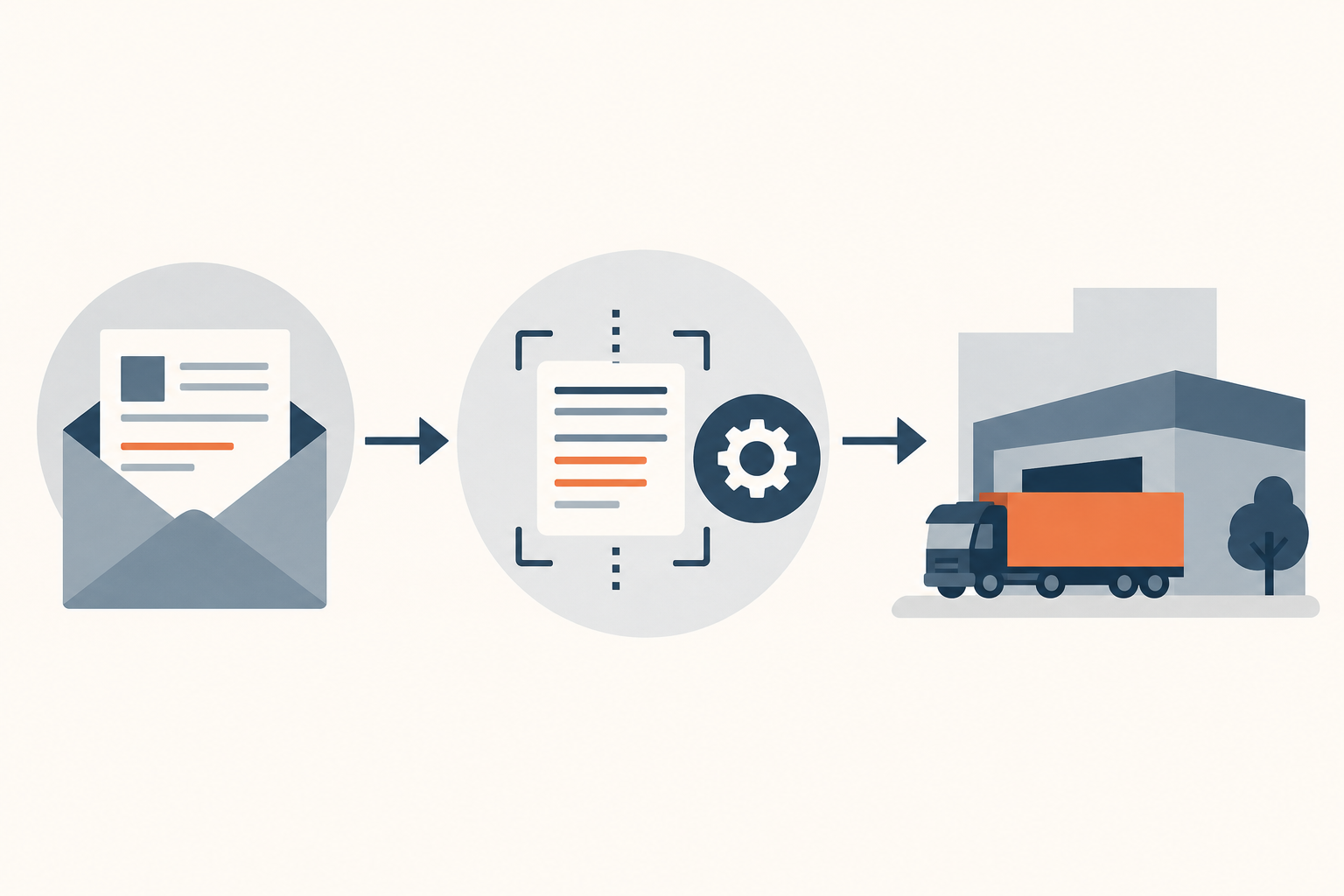
Viele mittelständische Speditionen und Verlader erfassen Transportaufträge noch manuell aus dem E-Mail-Postfach – ein Prozess, der täglich mehrere Stunden bindet, fehleranfällig ist und bei Auftragsspitzen zum Flaschenhals wird. Dieser Artikel erklärt, wie automatisierte E-Mail-Auswertung mittels KI-gestützter Texterkennung funktioniert, welche Voraussetzungen bestehen, was typische Stolperfallen sind und wann sich der Aufwand rechnet.
Wer in einer mittelständischen Spedition oder bei einem regionalen Verlader hinter die Kulissen schaut, findet oft denselben Ablauf: Disponenten öffnen morgens das geteilte Auftragspostfach, lesen E-Mail für E-Mail und tippen Ladeadressen, Zeitfenster, Referenznummern und Gewichtsangaben in das Transportmanagementsystem (TMS) oder die Lagerverwaltung. Dieser Prozess läuft in Tausenden Betrieben täglich ab – und er läuft meistens ohne jede Automatisierung.
Das ist kein Nischenphänomen. Laut einer Erhebung des Bitkom nutzen zwar viele Logistikunternehmen digitale Tools, doch die Auftragskommunikation per E-Mail bleibt in weiten Teilen des Mittelstands der dominante Kanal [1]. Der Grund: Während große Verlader und Konzernkunden über EDI-Schnittstellen nach GS1-Standard kommunizieren [3], senden kleinere und mittelgroße Auftraggeber Freitexte, eingescannte Formulare oder selbst gestrickte Excel-Anhänge. Eine universelle EDI-Einbindung scheitert an der Heterogenität der Absender.
Das Ergebnis ist ein struktureller Medienbruch. Die Information liegt digital vor – im E-Mail-Body oder als PDF-Anhang –, wird aber manuell re-digitalisiert, weil das Zielsystem (TMS, ERP) ein anderes Datenformat erwartet. Jede Übertragung ist eine potenzielle Fehlerquelle: eine falsche Ziffer in der Postleitzahl, ein vertauschter Termin, ein übersehenes Sondergewicht. Fehler an dieser Stelle erzeugen Folgekosten in der Disposition, beim Fahrer und im Reklamationsmanagement.
Die Digitalisierung der Logistik schreitet zwar voran, aber ungleichmäßig [2]. Während Lagerautomatisierung und Telematik bereits weit verbreitet sind, hinkt die vorgelagerte Auftragserfassung oft hinterher. Genau hier setzt die automatische E-Mail-Auswertung an.
Der technische Kern einer automatisierten Auftragserfassung aus E-Mails besteht aus mehreren aufeinanderfolgenden Schritten, die zusammen als Verarbeitungspipeline fungieren.
Im ersten Schritt wird jede eingehende E-Mail auf einem definierten Postfach abgegriffen – entweder per IMAP-Anbindung oder über eine API des genutzten Mail-Dienstes. Das System liest Betreffzeile, Absender, Nachrichtentext und alle Anhänge. Anhänge werden, sofern es sich um PDFs oder Bilddateien handelt, einer optischen Zeichenerkennung (OCR) zugeführt, die den Text aus dem Dokument extrahiert.
Im zweiten Schritt übernimmt ein Sprachmodell oder ein regelbasierter Extraktor die Aufgabe der Informationsstrukturierung. Hier wird aus dem Freitext ermittelt: Wer ist der Auftraggeber? Was sind Ablade- und Beladestellen? Welche Zeitfenster gelten? Welches Gewicht und welche Ladungsart sind angegeben? Dabei ist entscheidend, dass das Modell nicht nur exakt formatierte Tabellen lesen kann, sondern auch idiomatische Formulierungen wie „Bitte abholen bis Dienstag Mittag am Lager Süd" korrekt in einen Datensatz mit Datum und Standortbezug überführt. Genau das ist der qualitative Unterschied zu klassischen regelbasierten Systemen, die auf feste Feldpositionen angewiesen waren. KI-gestützte Texterkennung in Geschäftsprozessen arbeitet robuster gegenüber variierendem Layout und Formulierungsstil.
Im dritten Schritt erfolgt die Plausibilitätsprüfung: Das System gleicht die erkannten Adressen gegen das Stammdatensystem ab, prüft Zeitfenster auf Widersprüche (z. B. Abholdatum nach Lieferdatum) und validiert Referenznummern. Erst nach dieser Prüfung wird der Auftrag entweder direkt ins TMS geschrieben oder – bei niedrigem Konfidenzwert – zur manuellen Freigabe in eine Warteschlange gestellt.
Die Warteschlange ist kein Versagen des Systems, sondern ein bewusstes Designelement: Kein automatisiertes System wird lückenlos alle Aufträge korrekt erkennen. Eine durchdachte Ausnahmebehandlung – mit klarer Anzeige, was erkannt wurde und was fehlt – ist genauso wichtig wie die Erkennungsrate selbst.
Praktiker-Beobachtung: Ein typischer Fallstrick ist das sogenannte „Attachment-Sandwich": Der Auftraggeber sendet einen Auftrag mit PDF-Anhang, ergänzt aber entscheidende Informationen (z. B. das abweichende Lieferfenster) in der E-Mail-Body-Nachricht darunter – nicht im PDF. Systeme, die nur den Anhang auslesen, verpassen diese Information. Die Body-PDF-Kombination muss als einheitliche Informationsquelle behandelt werden.
Um die Wirtschaftlichkeit einer Automatisierungsinvestition einzuschätzen, braucht es eine realistische Bestandsaufnahme der aktuellen Prozesskosten. Die folgende Modellrechnung basiert auf angenommenen Werten, die für einen mittelständischen Stückgutbetrieb mit 40–80 Aufträgen täglich typisch sind.
Die folgende Tabelle ist eine Modellrechnung mit angenommenen Werten:
| Position | Wert |
|---|---|
| Eingehende Transportaufträge per E-Mail (täglich) | 60 |
| Durchschnittliche Bearbeitungszeit pro Auftrag (manuell) | 8 Minuten |
| Arbeitsminuten Erfassung täglich | 480 Minuten (8 Stunden) |
| Arbeitstage pro Monat | 22 |
| Monatliche Erfassungszeit | 176 Stunden |
| Angenommener Stundensatz Disponentin (inkl. Nebenkosten) | 38 €/Std. |
| Monatliche Personalkosten allein für Erfassung | 6.688 € |
| Fehlerquote manuell (angenommen) | 2 % der Aufträge |
| Fehler pro Monat | ca. 26 Aufträge |
| Nachbearbeitungsaufwand je Fehler (angenommen) | 25 Minuten |
| Zusatzkosten durch Fehlerkorrektur monatlich | ca. 415 € |
| Gesamte monatliche Prozesskosten (angenommen) | ca. 7.100 € |
Nach Einführung einer automatisierten Erfassung, bei der erfahrungsgemäß (angenommen) 70–85 % der Aufträge direkt und ohne manuelle Eingriffe verarbeitet werden, entfällt der Großteil dieser Zeit. Die verbleibenden Ausnahmen – also die Aufträge mit niedrigem Konfidenzwert – erfordern weiterhin manuelle Bearbeitung, allerdings wesentlich fokussierter: Das System zeigt bereits, was erkannt wurde, der Disponentin fehlt nur noch die Prüfung und Bestätigung. Erfahrungswerte aus vergleichbaren Digitalisierungsprojekten in der Logistik zeigen, dass die verbleibende Bearbeitungszeit für Ausnahmefälle deutlich unter der ursprünglichen Gesamtzeit liegt [7].
Der Nutzen liegt jedoch nicht allein in den Personalkosten. Schnellere Auftragserfassung bedeutet frühzeitigere Disposition, was bei knappen Ladezeiten oder Just-in-time-Lieferungen direkt in die Servicequalität einzahlt. Zudem sinken Übertragungsfehler, die im Reklamationsfall teurer werden als die reine Korrekturzeit.
Was die Investitionsseite betrifft: Die Implementierung einer solchen Lösung variiert stark je nach Integrationstiefe, genutztem TMS und gewähltem Ansatz (Eigenentwicklung vs. konfigurierte Standardlösung). Eine Pilotphase für einen einzelnen Auftraggeber oder eine Auftragsart lässt sich mit überschaubarem Aufwand umsetzen – hier empfiehlt sich ein stufenweises Vorgehen, wie es im ROI-Kalkül für Automatisierungsprojekte beschrieben wird.
Automatisierung ist kein Selbstläufer. Bevor ein Unternehmen in die Implementierung geht, lohnt eine ehrliche Bestandsaufnahme entlang von vier Achsen.
Stammdatenqualität: Die Automatisierung ist nur so gut wie die Daten, gegen die sie validiert. Sind Kundennummern, Adressen und Standortbezeichnungen im TMS widersprüchlich gepflegt – z. B. existiert ein Kunde unter drei verschiedenen Schreibweisen –, wird die automatisierte Erkennung häufig Alarm schlagen. Stammdatenbereinigung ist deshalb oft der erste, unattraktivste aber notwendigste Schritt.
Auftragsvolumen und Quellenkonzentration: Für Betriebe mit weniger als 20 E-Mail-Aufträgen täglich ist der ROI kurzfristig schwieriger darzustellen, sofern die Aufträge sehr heterogen sind. Je stärker der Auftragseingang auf wenige, wiederkehrende Auftraggeber konzentriert ist, desto schneller lernt das System deren Formatierungseigenheiten – und desto höher die Erkennungsrate.
Systemintegration: Eine API-Schnittstelle zum genutzten TMS oder ERP ist zwingend notwendig. Systeme, die keinen strukturierten Datenimport erlauben, erfordern Workarounds (z. B. CSV-Import), die die Prozesskette wieder unterbrechen. Vor Projektstart sollte die Integrierbarkeit mit dem Systemanbieter konkret geklärt sein.
Datenschutz und DSGVO: E-Mails enthalten personenbezogene Daten: Ansprechpartner, gelegentlich Mobilnummern von Fahrern, manchmal Empfängernamen. Werden diese E-Mails an externe Cloud-Dienste zur Verarbeitung übermittelt, muss ein Auftragsverarbeitungsvertrag (AVV) nach Art. 28 DSGVO vorliegen [5]. Verarbeitungsort und Datenhaltung müssen dokumentiert sein – das ist kein bürokratisches Detail, sondern ein ernstzunehmender Compliance-Punkt, besonders wenn Unternehmen mit öffentlichen Auftraggebern oder im Pharma-/Chemiebereich tätig sind. Mehr dazu im Überblick zum Datenschutz in der KI-Automatisierung unter der DSGVO.
Praktiker-Beobachtung: In der Praxis scheitern Projekte seltener an der Technik als an unklaren Zuständigkeiten innerhalb des Unternehmens. Die Frage, wer für die Ausnahmewarteschlange verantwortlich ist, muss vor dem Go-live beantwortet sein – sonst sammeln sich unbearbeitete Aufträge in der Queue, während der Disponentin nicht klar ist, ob sie dort nachschauen muss oder das System die Aufträge schon verarbeitet hat.
Eine strukturierte Einführung folgt einem bewährten Muster, das Risiken minimiert und gleichzeitig schnell erste Erfolge sichtbar macht.
Phase 1 – Analyse und Pilotauswahl (Wochen 1–3): Zunächst wird der aktuelle Prozess dokumentiert: Welche Auftraggeber senden per E-Mail? Welche Formate nutzen sie? Wie viele Aufträge kommen täglich, wöchentlich? Für den Piloten wird idealerweise ein Auftraggeber ausgewählt, der volumenstark, aber in seinem Auftragsformat konsistent ist. Drei bis vier Wochen historischer E-Mail-Verkehr werden für das Training und die Konfiguration genutzt.
Phase 2 – Konfiguration und Testlauf (Wochen 4–8): Das Extraktionsmodell wird auf die Felder des Zielsystems konfiguriert. In einem Schattenbetrieb – das System läuft parallel zur manuellen Erfassung, schreibt aber noch nichts ins TMS – werden Erkennungsgenauigkeit und Ausnahmeraten gemessen. Hier zeigen sich regelmäßig die typischen Problemfälle: E-Mails auf Englisch von internationalen Absendern, Aufträge mit mehr als zwei Ladestellen, angehängte Excel-Tabellen mit mehreren Aufträgen je Zeile.
Phase 3 – Produktivbetrieb mit Begleitung (Wochen 9–16): Der Produktivbetrieb beginnt zunächst nur für den Pilotauftraggeber. Die Ausnahmequeue wird täglich ausgewertet, um systematische Erkennungsprobleme schnell zu identifizieren. Nach vier bis sechs Wochen sollten Erkennungsrate und Fehlerquote stabil sein. Erst dann wird der Rollout auf weitere Auftraggeber ausgedehnt.
Phase 4 – Rollout und Optimierung: Mit wachsendem Auftragsvolumen im automatisierten Kanal wächst auch der Datenfundus für Anpassungen. Neue Auftraggeber oder geänderte Formate werden gezielt nachkonfiguriert. Wichtig: Es gibt keinen Endpunkt, an dem das System „fertig" ist. E-Mail-Formate ändern sich, neue Auftraggeber kommen hinzu. Ein kleines Budget für laufende Pflege muss eingeplant sein.
Die Grundprinzipien hinter diesem stufenweisen Vorgehen – zunächst Piloten definieren, Daten messen, skalieren – gelten gleichermaßen für andere Logistikprozesse. Der Leitfaden zur Prozessautomatisierung in der Logistik beschreibt das Vorgehen übergreifend für verschiedene Prozessarten.
Neben den bereits genannten Problemen bei Stammdaten und Zuständigkeit gibt es weitere typische Fehlerquellen, die in der Praxis immer wieder auftreten.
Mehrauftragsemails: Ein Auftraggeber schickt eine einzige E-Mail mit zehn Aufträgen für die nächste Woche – als Tabelle im Body oder als mehrseitiges PDF. Viele Systeme sind auf den Einauftrag-je-E-Mail-Fall optimiert. Mehrzeilige Tabellenformate müssen explizit als Sonderfall konfiguriert werden, sonst wird nur der erste Auftrag erkannt.
Weiterleitungen und Antwort-Ketten: Wenn eine Disposition-Mitarbeiterin eine Auftrags-E-Mail intern weiterleitet und der Auftragsinhalt dabei in einem Reply-Strang vergraben ist, kann das System die ursprüngliche Nachricht entweder doppelt verarbeiten oder gar nicht erkennen. Klare Regeln, welches Postfach als „Quelle" gilt und wie mit Weiterleitungen umgegangen wird, müssen vor Go-live festgelegt sein.
Sprachliche Varianz und Abkürzungen: Auftraggeber aus der Automobilindustrie nutzen andere Abkürzungen als Auftraggeber aus dem Lebensmittelhandel. „LKW", „TRK", „FTL", „40t" – das System muss diese Varianten kennen. Fehlende Synonyme im Konfigurationswörterbuch führen zu falsch klassifizierten Feldern.
Kein Feedback-Loop: Wenn Disponenten Ausnahmen aus der Queue manuell korrigieren, aber diese Korrekturen nicht systematisch zurückgespielt werden, lernt das System nicht. Ein strukturierter Feedback-Prozess – mindestens wöchentlich ausgewertete Korrekturen – ist kein optionales Feature, sondern eine Qualitätssicherungsmaßnahme.
Überhöhte Automatisierungserwartung: Die Erwartung, dass von Anfang an lückenlos alle Aufträge automatisch verarbeitet werden, führt zu Enttäuschung und voreiligem Projektabbruch. Eine realistisch kommunizierte Startzielgröße von z. B. 65–75 % vollautomatisch verarbeiteten Aufträgen (angenommen) ist ehrlicher und erlaubt, die restlichen 25–35 % als Ausnahmebehandlung professionell zu managen. Versteckte Kosten manueller Abläufe in KMU zeigen, warum selbst eine Teilautomatisierung wirtschaftlich attraktiv sein kann.
Praktiker-Beobachtung: Ein in der Praxis häufig unterschätzter Faktor ist das Verhalten der Disponenten nach der Einführung. Wenn das Vertrauen in das System fehlt, neigen erfahrene Mitarbeitende dazu, jeden automatisch erfassten Auftrag manuell nachzuprüfen – was den Zeitvorteil weitgehend neutralisiert. Vertrauen in das System muss aktiv aufgebaut werden: durch transparente Anzeige der Erkennungsqualität, durch regelmäßige Fehlerauswertung im Team und durch Einbindung der Disponenten in die Konfigurationsphase.
Die EU-eFTI-Verordnung (Electronic Freight Transport Information) verpflichtet Unternehmen im Güterverkehr schrittweise dazu, Frachtinformationen elektronisch bereitzustellen und zu akzeptieren [5]. Ziel ist die vollständig digitale Frachtdokumentation, die von Behörden ohne Papierdokumente geprüft werden kann. Die Verordnung ist bereits in Kraft; die praktische Anwendungspflicht wird schrittweise eingeführt.
Wer heute bereits Transportaufträge strukturiert digital erfasst – und nicht mehr als Freitext im E-Mail-Body –, schafft die Datenbasis, die eFTI-konforme Prozesse voraussetzen. Die Automatisierung der Auftragserfassung ist damit nicht nur ein Effizienzprojekt, sondern ein Compliance-Enabler.
Darüber hinaus registriert die Branche zunehmend, dass Verlader und Großkunden ihrerseits den Druck erhöhen, schnellere Auftragsbestätigungen und digitale Track-and-Trace-Informationen bereitzustellen. Wer Aufträge noch manuell überträgt, hat zwischen Auftragseingang und Bestätigung zwangsläufig eine Verzögerung. Automatisierte Systeme können eine Auftragsbestätigung unmittelbar nach der Plausibilitätsprüfung zurücksenden – ein Qualitätsmerkmal, das Auftraggeber zunehmend als Standard erwarten.
Auch der Fachkräftemangel in der Logistik ist ein strukturelles Argument: Wenn qualifizierte Disponenten schwieriger zu finden und zu halten sind [6], muss ihre Arbeitszeit auf anspruchsvollere Aufgaben – Kapazitätsplanung, Kundenbeziehungen, Ausnahmemanagement – konzentriert werden. Repetitive Dateneingabe ist kein sinnvoller Einsatz knapper Disponenten-Kapazität.
Praktiker-Beobachtung: Viele Betriebe unterschätzen, wie lange die interne Abstimmung zwischen IT, Disponenten und Geschäftsführung dauert, bevor ein Projekt tatsächlich startet. Wer mit regulatorischen Fristen plant, sollte sechs bis neun Monate Vorlauf für Entscheidungsfindung, Ausschreibung und Implementierung einkalkulieren – auch wenn die eigentliche technische Umsetzung deutlich kürzer dauert.
Ja, das ist sogar der primäre Anwendungsfall. Die Stärke KI-gestützter E-Mail-Auswertung liegt genau darin, dass kein strukturiertes EDI-Format beim Absender vorausgesetzt wird. Auftraggeber können weiterhin Freitexte, individuelle PDF-Formulare oder Tabellenanhänge schicken – das System extrahiert die relevanten Felder unabhängig vom Format. Voraussetzung ist lediglich, dass der Auftraggeber die Kernfakten (Ablade-/Beladestelle, Datum, Gewicht) in der E-Mail irgendwo nennt.
Falsch erkannte Aufträge werden nicht automatisch ins TMS geschrieben, sondern landen in einer Ausnahme-Warteschlange zur manuellen Prüfung. Jedes gut konzipierte System arbeitet mit Konfidenzwerten: Liegt die Erkennungssicherheit unter einem definierten Schwellwert, wird der Auftrag zur manuellen Freigabe markiert, mit Anzeige der erkannten und der fehlenden Felder. So bleibt der Disponent stets Letztentscheider bei unsicheren Fällen – die Automatisierung übernimmt nur, was sie mit ausreichender Sicherheit erkannt hat.
Als grober Richtwert (angenommen) gilt: Ab etwa 25–30 E-Mail-Aufträgen täglich wird die Investition in eine automatisierte Erfassung in der Regel innerhalb von zwölf bis achtzehn Monaten amortisiert, sofern die Auftraggeber hinreichend wiederkehrend sind. Bei sehr heterogenen Einzel-Auftraggebern verschiebt sich der Break-even weiter nach hinten. Entscheidend ist nicht nur das Volumen, sondern auch die Wiederholungsfrequenz der Formate: Je mehr sich die E-Mails eines Auftraggebers ähneln, desto schneller steigt die Erkennungsrate – und desto besser die Wirtschaftlichkeit.
Nein, eine tiefgehende technische Schulung ist nicht erforderlich. Disponenten interagieren in der Regel nur mit der Ausnahme-Oberfläche: Sie sehen vorausgefüllte Felder, prüfen diese und bestätigen oder korrigieren. Das ist intuitiv erlernbar und erfordert typischerweise ein bis zwei Stunden Einweisung. Wichtiger als technisches Schulungswissen ist das Verständnis, welche Aufträge automatisch verarbeitet werden und wann und warum ein Auftrag in die manuelle Prüfung landet – das schafft Vertrauen in das System.
DSGVO-Konformität erfordert vor allem einen gültigen Auftragsverarbeitungsvertrag (AVV) mit jedem Dienstleister, der die E-Mail-Inhalte verarbeitet. Zusätzlich muss dokumentiert sein, wo Daten gespeichert werden (EU oder Drittland), wie lange sie aufbewahrt werden und wer Zugriff hat. Für besonders sensible Auftraggeber oder Branchen empfiehlt sich eine On-Premise- oder Private-Cloud-Lösung, bei der keine E-Mail-Inhalte externe Server verlassen. Die Datenschutzanforderungen sollten bereits in der Ausschreibungsphase als verbindliche Kriterien formuliert werden.
Jetzt unverbindlich beraten lassen: Wie lässt sich Ihre Auftragserfassung automatisieren?
Mitgründer & Geschäftsführer Socialeap – Automatisierung & Softwareentwicklung
Sed at tellus, pharetra lacus, aenean risus non nisl ultricies commodo diam aliquet arcu enim eu leo porttitor habitasse adipiscing porttitor varius ultricies facilisis viverra lacus neque.